Testing Chatbots Is Different: Why Traditional UI Automation Falls Short and How AI Agents Fix It

Chatbots have changed the way users interact with software. Instead of clicking through rigid workflows, users now type questions, give instructions, ask for summaries, request charts, upload files, and expect intelligent responses. This shift has created a new testing problem that traditional automation tools were never designed to solve.
For years, teams have relied on tools like Selenium and Playwright to test web applications. These tools work well when the application behaves in a mostly deterministic way. A button click should open a modal. A form submission should show a success message. A table should contain a certain row. In these cases, testers can depend on locators, assertions, and exact text matching.
But chatbot testing is different.
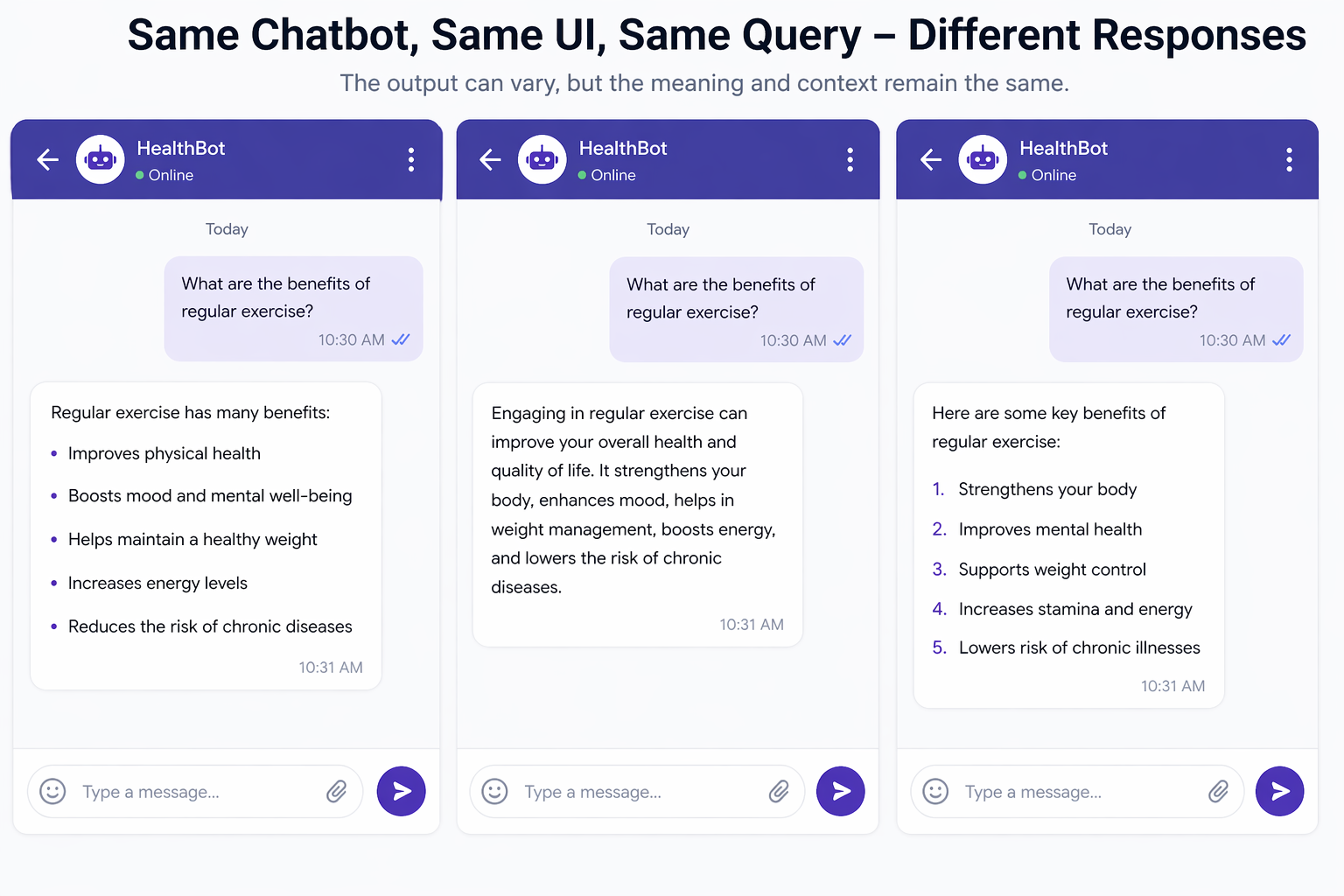
One of the biggest challenges in testing a chatbot is the non-deterministic nature of the response. The same user intent can produce different valid replies. A chatbot may answer in a shorter form one time, in a detailed form the next time, or format its response as bullets, paragraphs, tables, charts, or images. That makes deterministic validation extremely difficult.
This is where traditional automation starts to break down, and where AI-native testing becomes necessary.
DevAssure agent addresses this challenge by validating chatbot behavior using natural language instructions and LLM-based reasoning instead of brittle exact matches. Rather than expecting one fixed response, it evaluates whether the response is contextually correct, relevant, and complete. And when the chatbot responds with visual outputs such as images, graphs, or charts, DevAssure can use vision capabilities to understand and validate those as well.
This blog explores why chatbot testing needs a new approach, what goes wrong with traditional tools, and how AI agents can make chatbot testing practical, scalable, and reliable.
The Nature of Chatbot Responses
Traditional applications usually have a narrow set of expected outputs. When a user performs an action, the UI responds in a predictable way. Even when data is dynamic, the structure is often stable enough for automation to assert on the presence of specific elements or values.
Chatbots do not behave that way.
A user may ask:
- “Summarize this report”
- “Explain this graph”
- “Give me three action items”
- “Show me a comparison in table format”
- “Generate an image for this concept”
Even if the chatbot is functioning correctly, the exact response can vary every time. It may:
- use different wording
- reorder points
- choose a shorter or longer explanation
- present the result in a different format
- include extra helpful context
- omit non-essential phrasing while still being correct
This variability is not a bug. It is often a feature. Good conversational systems are expected to be flexible and adaptive.
That creates a core problem for testing: how do you validate correctness when there is no single exact string that must appear?
Why Traditional UI Automation Breaks for Chatbots
Tools like Selenium and Playwright are excellent for browser automation. They can navigate pages, click buttons, fill inputs, upload files, and read DOM content. They are foundational for E2E testing and remain extremely valuable for many kinds of applications.
But chatbot testing exposes their limits.
1. Exact text matching is too brittle
A traditional assertion may expect something like:
await expect(page.locator('.chat-response')).toHaveText('Your balance is $250');
This works only if the response is fixed. But a chatbot may say:
- “Your current balance is $250.”
- “You have $250 in your account.”
- “The available balance is $250 as of now.”
All of these may be correct. Exact matching turns valid responses into false failures.
2. Locators only validate structure, not meaning
A locator can tell you that a message bubble exists. It can tell you an image was rendered. It can tell you a chart container appeared. But it cannot tell you whether the answer is relevant, whether the chart is correct, or whether the explanation actually addresses the user’s question.
For conversational systems, semantic correctness matters more than structural presence.
3. Chatbots may return multiple valid formats
A single prompt may produce:
- plain text
- bullet points
- markdown tables
- code blocks
- inline images
- charts or graphs
- mixed content
Traditional UI assertions struggle when the output format itself is variable.
4. Responses are often context-dependent
A chatbot’s response can depend on:
- earlier messages in the conversation
- user-uploaded documents
- retrieval results
- system instructions
- user profile or permissions
- model temperature or inference behavior
Two test runs may differ in wording while still being equally valid. Conventional automation frameworks do not natively reason about conversational context.
5. Visual results are hard to validate meaningfully
If a chatbot generates an image, a graph, or a chart, traditional automation can verify that something was rendered. But it cannot determine whether the rendered content actually matches the request.
A chart can appear and still be wrong.
An image can load and still be irrelevant.
A graph can be present but misrepresent the data.
For chatbot systems, presence is not enough. Meaning must be tested.
The Real Problem: Deterministic Assertions on Non-Deterministic Systems
The mismatch is simple:
- Traditional testing expects deterministic output.
- Chatbots intentionally generate non-deterministic output.
Trying to force chatbot testing into exact-match assertions creates fragile tests, noisy failures, and high maintenance cost. Teams either end up with tests that fail for harmless phrasing changes or water down their assertions so much that they stop catching real quality issues.
This leads to a frustrating cycle:
- The team writes strict assertions.
- Valid chatbot responses fail the test.
- The team relaxes the assertions.
- Real correctness issues slip through.
- Trust in the tests drops.
The core issue is not that testing chatbots is impossible. It is that they need a different validation model.
A Better Approach: Natural Language Validation
Instead of checking whether the chatbot produced one exact response, the test should check whether the response satisfies the user’s intent.
That means validation should be expressed more like this:
- Does the answer correctly address the user’s question?
- Is the response factually aligned with the expected context?
- Does it contain the key concepts required?
- Is the tone or intent appropriate for the scenario?
- If a summary was requested, is it actually a summary and not a verbatim copy?
- If the chatbot refused, was the refusal appropriate and policy-aligned?
- If the chatbot returned a chart or image, does the visual output match the request?
These are semantic checks, not string checks.
And semantic checks are exactly where LLM-based validation becomes powerful.
How DevAssure Agent Solves Chatbot Testing
DevAssure agent approaches chatbot testing in a way that is much closer to how humans evaluate conversational systems.
Instead of relying only on locators or exact text matching, DevAssure uses natural language instructions to define the expected behavior. The response is then validated through LLM-based reasoning, allowing flexibility while still enforcing correctness.
This means the test can focus on intent and outcome rather than exact wording.
For example, instead of asserting:
“The response must exactly equal this sentence”
the test can validate:
“The chatbot should explain the refund policy clearly, mention the time window, and not invent unsupported conditions.”
This is a far more robust way to test a conversational system.
What This Enables
With an AI-driven validation approach, DevAssure can check whether:
- the chatbot answered the right question
- the answer is contextually correct
- the response covers the essential points
- the format is acceptable even if it varies
- the answer is safe, helpful, and relevant
- the chatbot handled ambiguity properly
- the output aligns with the user’s request, even when phrased differently
This reduces brittleness dramatically while improving the quality of validation.
Moving Beyond Exact Text: Validating Meaning
The biggest win in chatbot testing is moving from text equality to meaning validation.
Let us say the expected behavior is:
The chatbot should explain that password reset links expire after 24 hours and suggest requesting a new link if the old one is no longer valid.
A traditional assertion may fail because the response wording changed.
An LLM-based validator, however, can still pass the response if it correctly communicates:
- reset links are time-limited
- the expiration period is 24 hours
- the next step is to request a new reset link
The wording can vary. The meaning should not.
That is the right balance for chatbot testing: flexible language, strict intent validation.
Testing Chatbots With Rich and Visual Outputs
Modern chatbots do not just respond with text. They increasingly return:
- charts
- graphs
- infographics
- screenshots
- annotated visuals
- generated images
- mixed media responses
This introduces a second layer of testing complexity. Even if a system can semantically validate text, it still needs to understand visual content.
DevAssure agent handles this through vision capabilities.
That means the system can capture and analyze the content of visual outputs and validate whether they align with what the chatbot was supposed to produce.
Examples of Visual Chatbot Testing
Sales trend chart. A chatbot is asked to generate a sales trend chart. The validation should not stop at checking whether a canvas element appeared. It should evaluate whether a chart was actually rendered, whether it represents the requested metric, and whether the visual output matches the intended meaning.
Generated image. A chatbot is asked to create an image illustrating a concept. The validation should check whether the generated image is relevant to the prompt, not just whether an image tag exists.
Graph plus explanation. A chatbot responds with a graph plus a written explanation. The test should validate both the visual content and the explanation together, because correctness may depend on their consistency.
This is a major step beyond legacy UI automation, where visual outputs are often treated as opaque blobs unless manually inspected.
Real-World Chatbot Scenarios That Need Semantic Validation
Chatbot testing becomes much more practical when you think in terms of scenarios rather than fixed strings.
FAQ and Support Bots
A support chatbot may explain policies, steps, or account information in many valid ways. The test should verify correctness, completeness, and appropriateness, not exact phrasing.
RAG-Based Enterprise Assistants
When the chatbot retrieves information from documents, the test should verify whether the response is grounded in the provided context and whether it avoided hallucinating unsupported claims.
Analytics and Reporting Assistants
If the chatbot produces charts, insights, summaries, or comparisons, the test should validate both numeric interpretation and presentation quality.
Multimodal Chatbots
If the chatbot can generate images or interpret uploaded visuals, testing must cover visual correctness along with textual reasoning.
Workflow or Action-Oriented Assistants
If the chatbot helps users perform tasks, then the response must be judged based on whether it leads the user correctly and safely to the intended outcome.
Why This Matters More as AI Products Grow
Chatbot interfaces are no longer side features. In many products, they are becoming the product.
Teams are now building:
- AI copilots
- support assistants
- onboarding bots
- search assistants
- knowledge bots
- analyst bots
- multimodal agents
As these systems become business-critical, testing them with brittle automation is not enough. A chatbot that gives a slightly different but correct answer should not fail the build. A chatbot that gives a polished but wrong answer should absolutely fail the build.
That distinction is hard to capture with rigid assertions, but it is essential for product quality.
The testing strategy needs to align with how conversational systems actually behave in production.
Benefits of AI-Native Chatbot Testing
Using an agent like DevAssure for chatbot validation brings several practical advantages.
Lower Test Brittleness
Tests stop failing because of harmless wording changes.
Better Alignment With User Experience
Users care whether the answer is correct and helpful, not whether it matches a predefined string exactly.
Support for Dynamic Response Formats
The same test can tolerate valid differences in structure, formatting, and phrasing.
Stronger Validation for Conversational Quality
You can validate intent, relevance, completeness, and contextual correctness.
Multimodal Coverage
Text, images, charts, and graphs can all be validated in the same testing flow.
Reduced Maintenance
Teams do not need to constantly update assertions for minor content variations.
What Good Chatbot Tests Should Look Like
As chatbot systems evolve, good tests should focus on behavior and meaning. A strong chatbot test should define:
- The user intent — What is the user asking for?
- The expected semantic outcome — What must the chatbot communicate or accomplish?
- The allowed flexibility — What can vary without being considered a failure?
- The disallowed behavior — What would make the response incorrect, unsafe, incomplete, or misleading?
- The expected format or modality when relevant — Should the result be text, a summary, a table, a chart, or an image?
This approach produces tests that are much closer to real-world expectations.
From UI Automation to Outcome Validation
Traditional test automation has often been centered around mechanics:
- click this
- type that
- expect this element
- expect that text
For chatbot systems, the future is more outcome-driven:
- ask this question
- observe the response
- validate whether it is correct in context
- confirm whether the final output matches the user’s intent
This is a subtle but important shift.
The goal is no longer just to verify that the UI behaved mechanically. It is to verify that the system delivered the right answer.
That is exactly where AI agents become necessary, not optional.
The Future of Chatbot QA
As generative interfaces become more common, testing methods will need to evolve beyond traditional deterministic validation. Teams building AI products will need tooling that understands language, context, and visuals.
The future of chatbot QA will likely be shaped by systems that can:
- interpret the user’s intent
- reason about whether a response is correct
- validate multiple acceptable answer forms
- inspect visual outputs
- detect missing context, contradictions, and hallucinations
- evaluate quality from a user-centric perspective
This is not a replacement for all traditional testing. Selenium and Playwright still remain essential for many workflows. But for chatbot validation, they are only part of the story. They can automate the interaction, but they are not sufficient on their own to judge the response.
That judgment layer needs intelligence.
Testing Chatbots With the DevAssure O2 Agent
The DevAssure O2 Agent is built for the same kind of judgment-heavy flows that chatbots require. O2 is a context-aware testing agent: it can remember what has already happened in the run, drive the real browser (open pages, type, click, scroll, upload), and interpret natural-language steps with reasoning grounded in the current UI and the user’s intent—much closer to how an experienced tester would work than to a script of fixed selectors and exact strings.
That combination matters for chatbots because correctness is rarely “this exact text appeared once.” It is whether the latest reply still makes sense given the thread so far, what is visible on screen, and what the user was trying to accomplish. O2 can carry that context forward step by step, validate outcomes in flexible language, and still automate the mechanical parts of the session.
You define tests as YAML files under .devassure/tests in your project. Each case uses a short summary, a list of plain-English steps, optional priority, and tags. The full field layout and CLI commands (devassure init, devassure run-tests, filters, and more) are documented in the DevAssure O2 Agent CLI readme on npm.
Example: chatbot test case (YAML)
Below is a sample test in the same shape as the official example—steps are natural language, including semantic checks that tolerate different wording as long as the answer is correct in context:
summary: Support chatbot explains refund window without inventing policy
steps:
- Open the application url
- Go to the in-app support chat
- In the chat input, ask whether a refund is possible and what the time limit is
- Send the message and wait until the assistant’s reply is visible
- Verify the reply explains the refund rules in plain language, states the correct eligibility window if one exists, and does not promise terms that are not shown in the app or help content
- Ask a short follow-up that depends on the first answer, such as what to do if the purchase was a gift
- Verify the follow-up answer is consistent with the prior reply and still respects the same policy constraints
priority: P0
tags:
- chatbot
- support
- semantic-validation
After you add files like this under .devassure/tests, you run them with devassure run-tests (or devassure run) from the project directory, as described in the CLI readme. For chatbot-heavy products, tagging scenarios (for example chatbot, multimodal, rag) keeps those runs easy to filter when you only want conversational coverage.
Conclusion
Testing chatbots is fundamentally different from testing traditional web applications. The biggest challenge is the non-deterministic nature of the responses. The chatbot can answer the same intent in different ways, use different structures, and return outputs in text, images, graphs, or charts.
Traditional tools like Selenium and Playwright were built around locators and exact assertions. They work well for deterministic UI behavior, but they are not enough for validating conversational correctness.
DevAssure agent solves this by bringing natural language-driven validation into the testing process. Instead of depending on exact text, it evaluates the correctness of the response using LLM-based reasoning. That makes the validation flexible enough to handle response variation while still being strict about meaning and intent. And with vision capabilities, it can also validate rich outputs like images, charts, and graphs.
As chatbot products continue to grow, testing must move from rigid matching to intelligent validation. The teams that adopt this shift early will be better equipped to build trustworthy, scalable, and production-ready AI experiences.
If chatbot interfaces are the new front door for software, then chatbot testing needs to be just as intelligent as the systems it is testing.
🚀 See how DevAssure accelerates test automation, improves coverage, and reduces QA effort.
Ready to transform your testing process?