Why Your Coding Agent Can't Be Your Testing Agent

Last week, on a customer call, a CTO asked me the question I now get every single week:
"I'm already using Claude to write my code. Why can't I just point the same agent at the code and have it test itself?"
It's a fair question. If one AI can write a React component, surely it can write the test for that component too. The economics look seductive — one tool, one workflow, one bill.
But here's an insight:
Testing your own PR is like proofreading your own essay. You'll read it 10 times. You'll miss the same typo 10 times. Because your brain autocorrects what it wrote.
That insight is what this blog is about. And it explains why a coding agent, no matter how capable, is structurally the wrong tool to verify its own work.
The author cannot be the examiner
Imagine handing a textbook author the job of writing the final exam for their own book.
Two problems surface immediately -
- The exam will only test what the author thought to write down. Edge cases they didn't consider in the book won't appear in the exam either. The exam is a mirror of the textbook — it can never go beyond it.
- The questions will be phrased in the same mental frame as the chapters. The author "knows what they meant," so the exam asks students to recall and not to challenge - the material.
Now replace "textbook author" with "coding agent" and "exam" with "test suite." The shape of the problem is identical.
A coding agent that writes your function builds a mental model of what that function does. When you then ask the same agent to test it, the agent tests against that same model. It verifies its own assumptions. It doesn't challenge them. This isn't a bug in Claude or Cursor or any specific tool. It's the architecture of the situation. Whoever wrote the code is the worst person - or agent - to find what's missing from it.
"But, I can just prompt it to think like a tester"
This is the usual rebuttal. And it's where the build-vs-buy conversation actually begins for any CTO.
In theory, you can engineer a prompt that turns your coding agent into a tester. In practice, here's what that prompt would need to carry:
- Your historical bug patterns — "checkout flaked 4 times on Safari with autofill last quarter"
- Your real personas — 8-year-olds on tablets, admins on desktop, sales reps on flaky mobile networks
- Your usage patterns — when traffic spikes, which flows dominate, which are revenue-critical vs experimental
- Your design-system quirks — dropdowns inside modals losing focus on Firefox, that kind of thing
- Your environment matrix — staging vs prod, browsers, devices, network conditions
- Your last six months of incident postmortems
- A persistent memory of which user journeys are critical money paths
- Continuous awareness of the diff between the last green build and this PR
- The ability to actually open a real browser, click things, fill forms, and observe outcomes — not just read the code and imagine what would happen
Notice what just happened.
You didn't write a prompt. You described a product.
This is the real answer to the CTO question. Yes, you can spend three engineering quarters wiring all of the above into your coding agent's context and CI pipeline. At the end of that effort, you will have built — badly, and at the cost of your roadmap — what a dedicated testing agent already does out of the box. Build vs buy isn't an abstract debate here. It's the difference between treating testing as a side-feature of your coding tool, and treating testing as its own discipline that deserves its own agent.
What a testing agent actually does differently
A coding agent reads code and produces more code. A testing agent reads code and produces doubt - productive, structured, executable doubt.
DevAssure's O2 is positioned as a PR-native testing agent, and the workflow makes the difference concrete. A developer opens a pull request. O2 reads the diff, maps which user journeys are affected by the changed lines, checks what tests already exist for those journeys, identifies gaps, generates the missing tests, runs them in a real browser, and reports back — all before the PR gets merged.
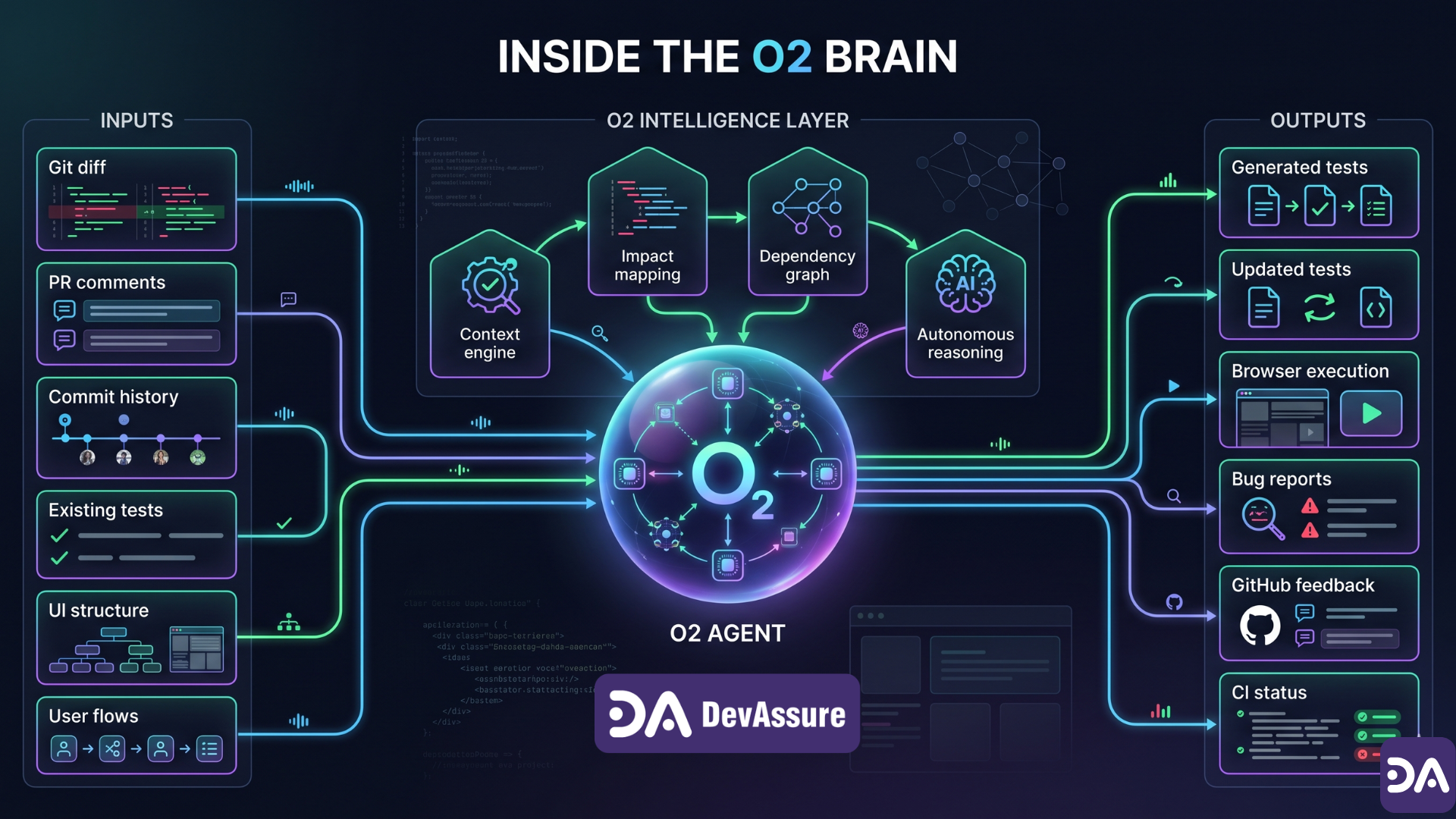
A few things in that loop are worth pulling out, because they're the exact things a coding agent in self-test mode cannot do.
It comes in with no mental model. O2 wasn't there when the code was written. It has no assumptions to confirm. It reads the diff cold, the way a senior QA engineer on their first day at the company would - except it does it in two minutes, on every PR, for every diff.
It thinks in personas, not endpoints. A coding agent will happily verify that POST /api/checkout returns 200. A testing agent verifies that a first-time mobile user with autofill enabled and an expired saved card can complete checkout. DevAssure has explicitly built persona definitions into the agent - so it simulates who is using the app, not just what the app exposes. An 8-year-old on a tablet, an admin on a desktop, a power user with keyboard shortcuts - each surfaces different bugs.
It actually runs the code. This is the line worth tattooing on every dev tools team's wall: "Code review doesn't run the code. It reads it. It imagines the behavior." A coding agent doing self-review is essentially a very fast code reviewer that imagines very hard. A testing agent opens the browser, performs the click, and watches what actually happens.
It maintains itself. When the UI changes, and it always does, a coding agent's generated test suite quietly rots until someone notices the assertions are out of date. O2 re-scopes to the new diff and updates tests in place. The maintenance loop that usually kills in-house automation efforts isn't your problem anymore.
The three failure modes of self-testing
When teams try to make a coding agent double as a tester, here's what tends to happen in production:
1. Tests that mirror the code, not the user. The agent generates assertions that match the implementation it just wrote. If the implementation has a bug, the test has the same bug. Both pass. Production breaks. A classic confirmation cascade.
2. Drowning in green checkmarks. Every PR ships with a sprawl of generated tests. They all pass. Coverage metrics look excellent. The actual user journey - the one your top 100 customers run every Monday morning - was never tested, because the agent didn't know it was important. False signal is worse than no signal.
3. The maintenance treadmill. Six months in, half the suite is flaky, nobody trusts the red, the team starts merging on yellow, and the whole automation effort silently becomes theater. This is the failure mode that bites CTOs hardest, because it shows up after you've already committed engineering quarters to the path.
The unifying theme: a coding agent optimizes for "the code I wrote works." A testing agent optimizes for "the user succeeds." Those are not the same goal, and you can't prompt your way from one to the other. The coding agent is the worst agent to test it. That's not a limitation of AI - it's a feature of how testing has always worked.
The specialization argument, in one line
We don't ask the architect to be the building inspector. We don't ask the defense lawyer to be the prosecutor. We don't ask the author to grade their own exam.
The reason isn't that any of them is bad at their job. The reason is that the second role requires the absence of the first one's context. Skepticism is a structural property, not a personality trait. Once you've built the mental model, you can't un-build it for the purposes of attacking your own work.
For CTOs evaluating the AI stack, the takeaway compresses to this: your coding agent and your testing agent should be different agents - not for vendor diversity, but because they are doing fundamentally opposite jobs. One builds the mental model. The other refuses to share it.
Where this leaves you
If you're a developer, the next time you reach for your coding agent to also test what it just wrote, ask yourself the proofreading question. Will you catch the typo your own brain just put there? Probably not. Bring in fresh eyes, and ideally, fresh eyes that can also run the code.
If you're a CTO, the build-vs-buy answer is now clearer. You can spend a year teaching your coding agent to test, or you can plug a dedicated testing agent like DevAssure O2 into your PR pipeline right now. Both paths get you to the same destination. Only one of them lets you ship in the meantime.
The agent that wrote the code is the worst agent to test it. That's not a limitation of AI - it's a feature of how testing has always worked.
Links
- O2 Agent: https://www.devassure.io/o2-testing-agent
- Persona Testing: https://www.devassure.io/blog/persona-testing/
- DevAssure O2 on GitHub Marketplace: https://github.com/marketplace/actions/devassure-action
- DevAssure: https://www.devassure.io
- CLI: https://www.npmjs.com/package/@devassure/cli