The Quiet Death of the Test Script

For twenty years, automated testing meant writing more code. That era is ending — and most teams haven't noticed yet.
The first automated test I ever wrote was in Playwright. It was 2012. It launched a browser, filled in a login form, and checked that the dashboard loaded. It passed. I felt like a wizard.
More than a decade later, the fundamental contract hasn't changed. To test software, you write more software. You describe, in code, what your code is supposed to do. Then you maintain that second codebase forever.
We've built entire careers, conferences, certifications, and consultancies on this premise. Selenium. Cypress. Playwright. Test pyramids. BDD. Page object models. The whole apparatus rests on a single assumption: humans must specify, in writing, what to test.
That assumption is quietly dying.
The contract that never changed
If you've shipped production software in the last decade, you know the ritual.
A feature lands. Someone — often a senior engineer who'd rather be building — writes a Playwright spec or a Cypress flow. Selectors get debated. CI turns green. Six months later, a redesign breaks forty tests, and the team debates whether to fix them or delete them and pretend coverage still exists.
We normalized this. We called it test automation. We measured success in lines of test code and percentage coverage. We hired SDETs to tend the garden.
The garden kept growing. The product moved faster. The garden couldn't keep up.
The cost no one wanted to talk about
Walk into any engineering org with more than fifty developers and look at the QA budget. Not the QA team — the budget. Add up the engineering hours spent writing tests, fixing flaky tests, debugging CI failures that turned out to be test issues, and onboarding new engineers to the testing framework.
In most organizations, it's a number nobody wants printed.
The dirty secret of modern engineering is that we don't have a quality problem. We have a test maintenance problem. We ship slowly not because we lack confidence in our code, but because we lack confidence that our tests still describe what our code is supposed to do.
Every refactor breaks tests. Every UI redesign breaks tests. Every framework upgrade breaks tests. The tests, in many codebases, have become the slowest-moving part of the system — a calcified layer that constrains how the actual product can evolve.
We don't have a quality problem. We have a test maintenance problem.
Industry data consistently puts test maintenance at 40–50% of automation budgets. That's not a tooling bug. It's the structural cost of treating tests as permanent artifacts in a world where the application changes every sprint.
What changed
Three quiet developments converged. None of them arrived with a keynote. All of them matter.
1. Language models learned to read code
The first shift is that large language models got genuinely good at reading code. Not summarizing it, not autocompleting it — reading it, with structural understanding. Tracing a function call through three layers of abstraction is now within reach of a foundation model.
That matters because testing has always been a reasoning problem dressed up as a scripting problem. "What could break if this changes?" is a question about blast radius, dependencies, and user impact — not about whether your data-testid still resolves.
2. Browsers became commodity infrastructure
The second shift is economic. Spinning up a clean Chromium instance for thirty seconds costs fractions of a cent. The constraint that pushed teams toward minimal, hand-written test suites — we can't afford to run much — no longer binds the way it did when Selenium grids lived on rented VMs and every minute in CI was negotiated.
Real-browser execution at PR time is no longer a luxury reserved for release candidates. It's table stakes for anyone serious about agentic test automation.
3. Git diffs became a signal of intent
The third shift is the one most teams still underweight: git diffs are a near-perfect signal of intent.
If you know exactly what changed in a pull request, and you can reason about how that change propagates through the codebase, you can validate it without referring to any pre-written script. The diff tells you what the author believed they were changing. A capable agent can ask whether that belief holds in a real browser, against real flows, for real users.
Put those three together and you get a new shape of testing:
An agent that reads the change, understands the blast radius, generates the tests that matter for this specific commit, runs them, and disappears.
Nothing to maintain. Nothing in the repository. Nothing for the next engineer to inherit and curse.
This is what DevAssure O2 does. It's what a handful of other tools are starting to do. And it's a fundamentally different relationship with testing than anything the last two decades produced.
Ephemeral tests vs. the second codebase
The old model optimized for reuse: write once, run forever, update when someone remembers.
The emerging model optimizes for relevance: generate what this change needs, run it, discard the scaffolding. The intelligence lives in the agent and the diff — not in ten thousand lines of selectors aging in a /e2e folder.
| Traditional test scripts | Ephemeral, PR-native testing | |
|---|---|---|
| Unit of work | Feature or page | This commit |
| Artifact | Permanent repo file | Generated, run, gone |
| Maintenance | Ongoing engineer time | Agent re-scopes per diff |
| Failure mode | Flaky, stale, ignored | Missed coverage on a PR |
| Best for | Stable, slow-changing surfaces | Fast-moving product teams |
This isn't an argument against all scripted tests. Unit tests around pure logic still earn their keep. API contract tests with stable schemas still make sense.
It's an argument that the dominant E2E strategy of the 2010s — a growing second codebase mirroring the UI — is reaching the end of its useful life for teams that ship continuously.
If you want the longer structural case for why scripts were the wrong abstraction to begin with, we wrote that separately: Your Team Should Not Be Writing Test Scripts.
How O2 fits the new model
DevAssure's O2 is a PR-native testing agent. The loop looks like this:
- A developer opens a pull request.
- O2 reads the diff and maps which user journeys are in the blast radius.
- It checks what coverage already exists, identifies gaps, and generates the tests that matter for this change.
- It runs them in a real browser — not by imagining behavior from static code review.
- It reports back before merge.
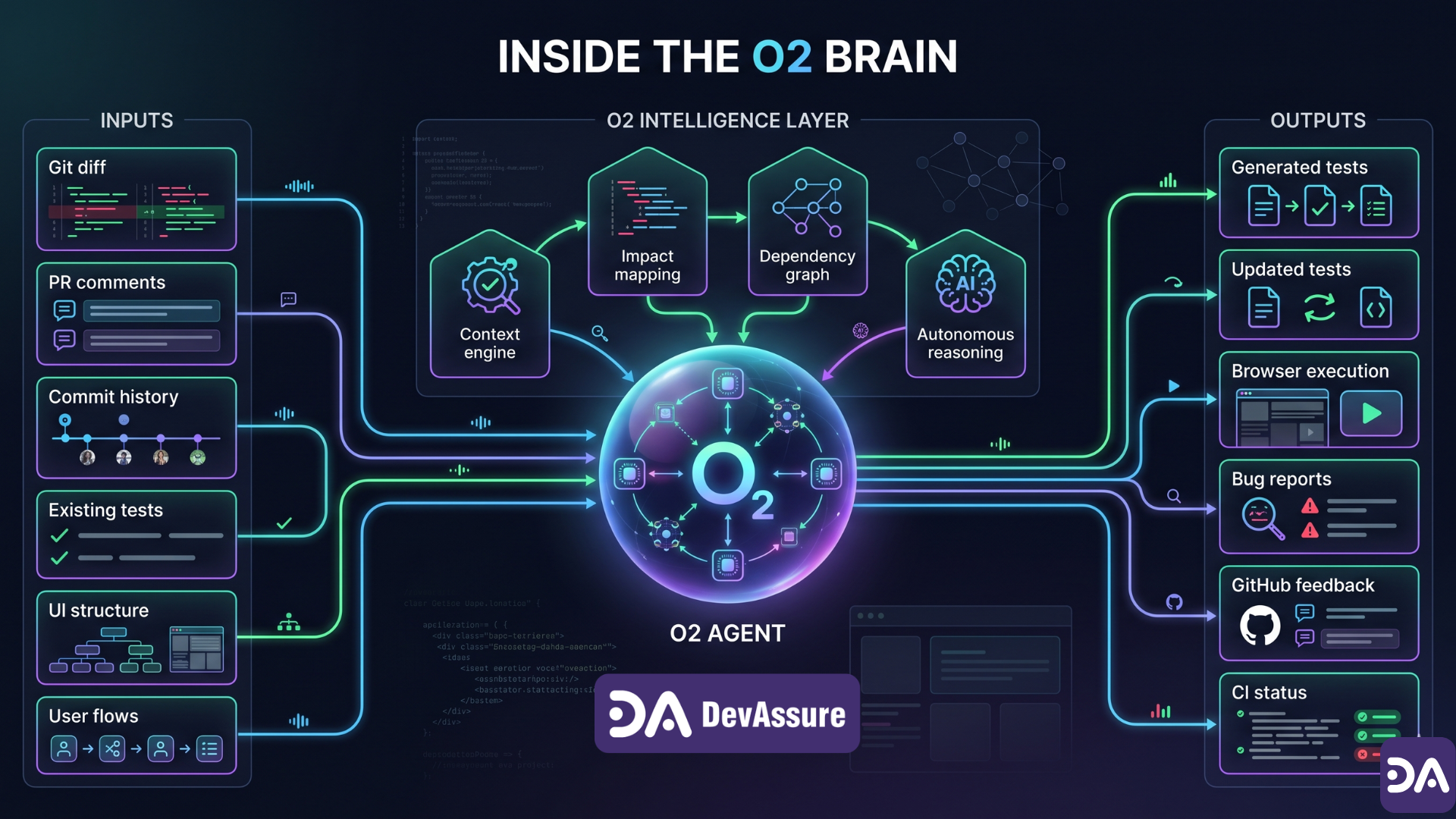
A few properties of that loop are worth naming explicitly, because they're the opposite of "write a Cypress test and hope it still makes sense in Q3":
No inherited mental model. O2 wasn't in the room when the feature was designed. It reads the diff cold — the way a sharp QA engineer on day one would, except it does it on every PR in minutes.
Persona-aware, not endpoint-aware. Verifying POST /api/checkout returns 200 is not the same as verifying a first-time mobile user with autofill and an expired card can finish checkout. O2 is built to think in personas, not just APIs.
Nothing to rot in the repo. When the UI changes next sprint, you don't open a ticket to fix selectors. The next diff triggers a fresh scope. The maintenance treadmill — the one that kills most in-house automation — isn't your problem anymore.
For teams already comparing build vs buy on AI testing, the adjacent read is why your coding agent can't be your testing agent — same era, different failure mode.
The transition won't be neat
Engineers don't like giving up control, and they especially don't like giving it up to systems they can't fully audit.
The first time an autonomous agent decides not to run a test you would have written, there's a moment of vertigo. What if it's wrong? What if it missed something?
These are fair questions. The answer, slowly emerging, is the same answer that emerged for compilers replacing assembly, for garbage collectors replacing manual memory management, for cloud infrastructure replacing colocated servers.
The new layer isn't perfect. It's just better than what most teams were doing in practice — because what most teams were doing in practice was already imperfect, just in ways we'd normalized:
- Tests that mirror the implementation and share its bugs
- Green CI with no confidence in critical user paths
- Suites so flaky that teams merge on yellow and call it culture
The specialization argument applies here too: the agent that wrote the code is structurally the worst agent to attack it. Fresh eyes — or a dedicated testing agent with no stake in the diff — aren't a nice-to-have. They're the point.
What this means for your team
In five years, "I wrote a Cypress test for that" will sound the way "I wrote that in jQuery" sounds now. Quaint. A relic of when we had to do everything by hand.
The teams that move first will save thousands of engineering hours. The teams that move last will spend those hours explaining to new hires why the test directory is twice the size of the source code.
If you're a developer: notice how long it's been since you wanted to write an E2E test. Notice how often you fix one instead. That friction isn't laziness — it's signal.
If you're a CTO: the build-vs-buy question isn't whether AI can generate tests. Copilot already does. The question is whether you want to own the maintenance of those tests forever, or whether you want an agent that shows up per PR, does the work, and leaves nothing behind.
The test script isn't dying with a bang. It's dying the way most things in software die — gradually, then all at once, while everyone insists it's still essential right up until the moment they realize they haven't written one in months.
Links
- DevAssure O2: https://www.devassure.io/o2-testing-agent
- Why coding agents can't test their own code: https://www.devassure.io/blog/why-coding-agents-cant-test/
- Your team should not be writing test scripts: https://www.devassure.io/blog/autonomous-test-execution/
- Persona testing: https://www.devassure.io/blog/persona-testing/
- DevAssure O2 on GitHub Marketplace: https://github.com/marketplace/actions/devassure-action
- DevAssure: https://www.devassure.io
- CLI: https://www.npmjs.com/package/@devassure/cli