Microsoft Just Built a Framework to Test AI Agents.

Short answer
At Microsoft Build 2026, Microsoft shipped ASSERT (policy-driven agent evaluation) and ACS (runtime agent governance) — because the agent that writes the code cannot be the agent that grades the code. That is the same principle behind DevAssure O2: independent, browser-based testing on every PR, written in plain English, with no scripts to maintain.
At Microsoft Build 2026, Microsoft announced something that quietly confirms the core thesis behind DevAssure: as AI agents take over more of the software development lifecycle, the agent that writes the code cannot be the agent that grades the code.
The announcement was a pair of open-source projects — ASSERT (Adaptive Spec-driven Scoring for Evaluation and Regression Testing) and the Agent Control Specification (ACS) — designed to give developers a portable, framework-agnostic way to evaluate and govern AI agents before their behavior ships to production. Coming from the company now positioning itself as the "agent-first" platform for enterprise development, this is a meaningful signal about where the industry is heading.
I want to walk through what Microsoft actually shipped, why it matters beyond agent safety, and what it means for teams where 30–40% of code is already AI-generated — because the validation gap Microsoft just named at the agent layer is the same gap most engineering teams still have at the application layer.
What Microsoft actually announced
Stripped of the keynote polish, ASSERT and ACS solve two different but related problems in the AI agent stack.
ASSERT: Turn policies into executable evaluations
ASSERT takes your written policies — what your agent should and shouldn't do — and turns them into actual test cases. It generates scenarios, runs them against your agent, and scores the results with reasoning attached, so you can see why something passed or failed, not just a pass/fail flag.
Key properties worth noting:
- Spec-driven: Natural-language requirements (product specs, policy docs, system prompts, launch checklists) become full evaluation pipelines — scenarios, datasets, metrics, and scorecards.
- Framework-agnostic: Works across LangChain, CrewAI, LiteLLM, and other stacks, with early ecosystem backing from CrewAI, Arize AI, Pydantic, and others.
- Evidence-rich scoring: For agentic systems, ASSERT records tool calls, retrieved context, routing behavior, and intermediate actions — not just final text output.
- Open source: MIT-licensed, available at github.com/responsibleai/ASSERT.
Microsoft describes ASSERT as built on a proven Microsoft Research approach: take organizational intent, systematically generate targeted evaluation scenarios, and surface safety and quality defects before they reach production.
ACS: Portable runtime governance for agents
ACS is the enforcement layer. It defines specific checkpoints in an agent's lifecycle — input, model call, state, tool execution, output — where deterministic controls can be applied. Think of it as a standardized way to say "no matter what framework you built this agent in, here's where the guardrails go and how they're declared."
Microsoft is positioning ACS as the agent-world equivalent of how MCP standardized tool access or A2A standardized agent-to-agent communication. Key details:
- Five validation checkpoints across the agent lifecycle.
- Deterministic control logic — classifier endpoints, LLM judges, custom content filters — placed exactly where you need them.
- Portable policy YAML — controls are versionable, auditable, and framework-independent.
- SDK with adapters for LangChain, OpenAI Agents SDK, Anthropic Agents SDK, AutoGen, CrewAI, Semantic Kernel, MCP tools, and more.
ACS ships as part of Microsoft's broader Agent Governance Toolkit (AGT), but the specification itself is vendor-neutral and developed in the open.
The closed loop Microsoft is proposing
Put together, the workflow looks like this:
1. Write policies → what the agent should and should not do
2. ASSERT evaluates → generate scenarios, run, score with reasoning
3. Find failures → identify where the agent violates policy
4. ACS enforces → apply controls at lifecycle checkpoints
5. Re-evaluate → confirm the fix worked before production
That is a closed loop from policy to production confidence — and it is structurally sound. Evaluate independently. Enforce deterministically. Re-evaluate to confirm.
Why this matters
Microsoft did not build ASSERT because agents are occasionally wrong. They built it because agents fail in ways that are hard to see, and generic benchmarks do not catch failures that are specific to your policies, your product, and your users. That is an argument for independent evaluation — not self-assessment.
Two layers of validation — and most teams only have one
Here is the part that should catch the attention of anyone building or shipping software with AI coding agents.
Microsoft built ASSERT and ACS because an agent's self-assessment isn't sufficient evidence that it's working as intended. That sentence could have come straight from a DevAssure pitch deck — except we've been making this argument about application-level testing, not just agent governance.
| Layer | What gets validated | Microsoft's answer | DevAssure's answer |
|---|---|---|---|
| Agent behavior | Did the agent follow policy, stay in scope, avoid unsafe tool calls? | ASSERT + ACS | N/A — not our layer |
| Application behavior | Does the code the agent wrote actually work for a real user in a browser? | Not addressed | DevAssure O2 |
If Microsoft's own Responsible AI team felt the need to build dedicated, independent tooling to evaluate whether their agents behave correctly against their requirements, the same logic applies with even more force to the applications those agents are building.
When a coding agent — Claude Code, Copilot, Cursor, Devin, whatever your team uses — opens a pull request, that PR represents the agent's own judgment about what "done" looks like. The agent decided what to build, how to build it, and in many cases, what tests should pass.
ASSERT exists because Microsoft recognizes that gap at the agent-infrastructure layer. The same gap exists at the application layer every time an AI-generated PR merges on the strength of unit tests the same agent wrote.
The author cannot be the examiner
This is the structural argument we've made since DevAssure's pivot to O2: the author cannot be the examiner.
Microsoft just built an entire open-source framework around a version of that same insight. The parallel is exact:
I wrote about this in depth in Why Your Coding Agent Can't Be Your Testing Agent. The proofreading analogy holds: you will read your own essay ten times and miss the same typo ten times, because your brain autocorrects what it wrote.
A coding agent that writes your function builds a mental model of what that function does. When you then ask the same agent to test it, the agent tests against that same model. It verifies its own assumptions. It doesn't challenge them.
This isn't a bug in Claude or Cursor or any specific tool. It's the architecture of the situation. Whoever wrote the code is the worst person — or agent — to find what's missing from it.
Microsoft's ASSERT team arrived at the same conclusion from the agent-governance side. We arrived at it from the application-testing side. The insight is identical.
What this means for teams shipping AI-generated code
If you're a team where 30–40%+ of your code is now AI-generated — and Tricentis CEO Kevin Thompson has cited figures in that range for 2026 — the Microsoft announcement is a useful external validation point for a conversation that's often hard to have internally:
"Our AI moves fast, but how do we know what it ships actually works for a real user?"
ASSERT and ACS are aimed at agent behavior — did the agent follow policy, stay in scope, avoid unsafe actions. They're not aimed at validating whether the application the agent built actually functions correctly in a browser, end to end, the way a real user would experience it.
That's a different layer of the stack, and it's the layer where most teams currently have the least coverage. Writing and maintaining UI-level E2E tests has historically been slow, brittle, and expensive �— which is exactly why so many teams skip it and lean on unit tests the agent wrote for itself.
The confirmation cascade
When a coding agent writes both the implementation and the test, the test often mirrors the implementation. If the implementation has a bug, the test has the same bug. Both pass. Production breaks. ASSERT was built to prevent this at the agent layer. O2 is built to prevent it at the application layer.
The recommended validation stack in 2026
For teams using AI coding agents, the quality stack now has three layers — and Microsoft just formalized the first one:
Layer 1: ASSERT + ACS → validates agent behavior against policy
Layer 2: DevAssure O2 Agent → validates application behavior in a real browser
Layer 3: Human review → validates judgment, UX, and business context
Microsoft just spent a Build keynote explaining why Layer 1 is non-negotiable for agents. The same logic applies to Layer 2 for what those agents build.
Where DevAssure O2 fits
We built DevAssure O2 for the application layer that ASSERT and ACS do not cover.
O2 is an autonomous testing agent that integrates into CI/CD via GitHub Actions. When a PR opens — whether the code was written by a human, Cursor, Copilot, or any other agent — O2:
- Reads the diff with zero prior assumptions — it wasn't there when the code was written
- Maps affected user journeys from the changed lines
- Generates and runs tests in a real browser, in plain English
- Reports results as a PR comment before merge
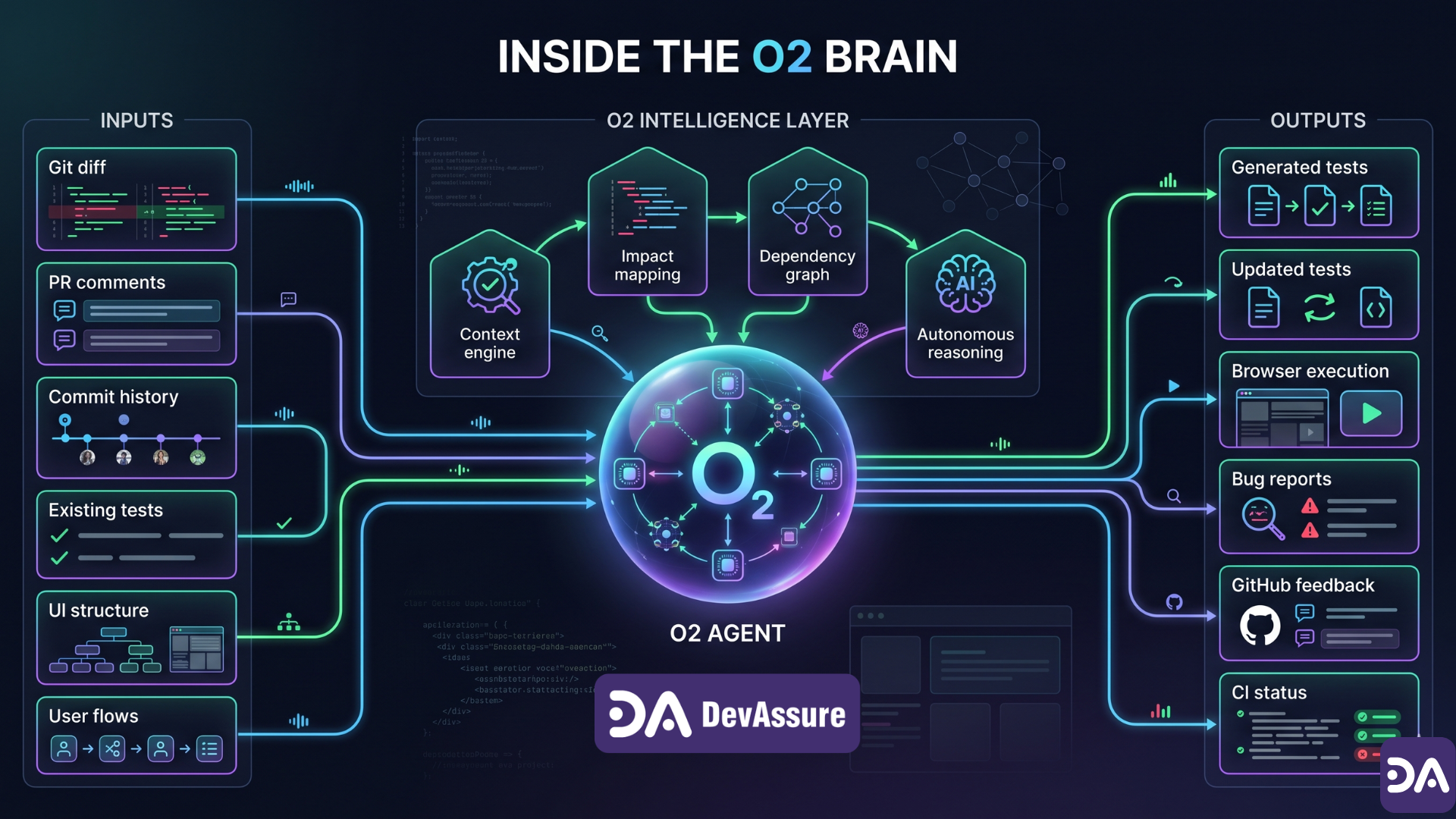
The key property: O2 has never seen the code before. It has no model of what the code should do. It reads what changed and asks what could break for a real user.
That is the same structural separation Microsoft just built ASSERT around — applied to pull requests instead of agent policies.
# One line in your CI/CD — every PR gets independent testing
steps:
- uses: devassure-ai/devassure-action@v1
No Selenium scripts. No locator maintenance. No test suite the coding agent authored. One YAML line, and every PR gets tested by something other than the agent that wrote it — in under 30 minutes.
For setup details, see How to Set Up Vibe Testing on Every Pull Request.
What engineering leaders should do now
If your team is already running AI coding agents, here is a practical framework — informed by Microsoft's Build 2026 announcement and what we see across customer deployments:
See also Google I/O 2026 and agentic coding — another major platform bet on agent-generated code with the same validation gap — and Shift Left Failed — Autonomous Testing Is What Comes Next.
The bottom line
Microsoft Build 2026 is the clearest enterprise signal yet that independent evaluation of AI output is not optional — it is infrastructure.
ASSERT and ACS validate that insight at the agent-governance layer. DevAssure O2 validates it at the application layer. They are complementary, not competitive. If you are building agents, adopt ASSERT. If those agents — or any coding tool — are writing your application code, you need something like O2 on every PR.
Microsoft just spent a Build keynote explaining why the agent that writes cannot be the agent that grades. The same logic applies to what those agents build.
Speed is the default now. Everyone gets Copilot. Everyone gets Cursor. Everyone gets ASSERT for their custom agents. The differentiator is confidence — shipping fast and knowing it works for a real user.
That is the problem we are solving at DevAssure.
Related reading
- Why Your Coding Agent Can't Be Your Testing Agent
- Google I/O 2026: Agentic Coding and Testing
- How to Set Up Vibe Testing on Every Pull Request
- Shift Left Failed — Autonomous Testing Is What Comes Next
- DevAssure O2 on GitHub Marketplace
Frequently asked questions
ASSERT (Adaptive Spec-driven Scoring for Evaluation and Regression Testing) is an open-source Microsoft framework that converts natural-language policies and requirements into executable evaluation pipelines. It generates test scenarios, runs them against AI agents or models, and scores results with reasoning — so teams see why something passed or failed, not just a boolean flag. It works across LangChain, CrewAI, LiteLLM, and other stacks.
Links
- DevAssure O2: https://www.devassure.io/o2-testing-agent
- DevAssure: https://www.devassure.io
- GitHub Action: https://github.com/marketplace/actions/devassure-action
- Microsoft ASSERT: https://github.com/responsibleai/ASSERT
- Microsoft ACS: https://github.com/microsoft/agent-governance-toolkit
- CLI: https://www.npmjs.com/package/@devassure/cli
Sources: Microsoft Foundry Blog — "Build agents you can trust across any framework with open evals and a control standard," June 2, 2026; Microsoft Command Line — ASSERT; Microsoft Command Line — ACS.